
Table of Contents
BLUF:
This document will cover research into Gootkit search term research as well as research possible verification methods.
Intro:
Gootkit research depends on having high quality methods to find the lure articles. This will explore using AI, country-specific search dorks, and SEO Keyword Planning tools to find Gootkit search terms. I will also explore ways to confirm if a URL is a Gootkit lure article, and ways to enumerate all of the articles within a domain.
Background:
The Gootkit Crawler is a project that I’m working on. Ideally, it will crawl the internet for Gootkit lures, find additional lure articles hosted on a Gootkit lure domain, and generate research products.
Lure article discovery:
The first problem is finding a search term to find Gootkit lures. One constraint is that a SOC Analyst might not be able to blog about the specific lure title/URL that they processed an incident on because of NDAs. Another constraint is that a new/aspiring Cyber person might not know how to start.
Lure article ideas:
After figuring out what would work the best, my next question is “How does the Gootkit Actor choose the lure ideas?”. If we figure this out, it may enable us to anticipate future Gootkit search terms.
Research:
Research into lure article discovery:
One easy method is to repeat specific terms observed from other reports. In our previous article “Is Gootkit Updating Their C2 Infrastructure?” (https://malasada.tech/is-gootkit-updating-their-c2-infrastructure/), we showed the snip that contained the URL of the Gootkit lure article. I also hovered over the link, so it shows the next server that will serve the ZIP and JS file. You can use the previously observed lure domains, and crawl them for other lure article titles. The downside is that the lure titles are unique to the domain, and you won’t be able to search for other lures using verbatim lure titles. Still, this is useful for an enthusiast because they can repeat the steps. Additionally, a SOC Analyst can use a different lure article from the lure domain if they wanted to demonstrate to their friends or family.
Another method to discover Gootkit lure articles is by using search dorks. These are just web searches that specify the domain with the “site” field as in “site:*.it enterprise agreement”. This is a useful one for me because it is strange and suspicious to see an enterprise agreement themed article from an Italian site. There are legitimate sites and articles, but most of those are from American companies that have a .IT TLD to do business (I’m guessing this is why) in Italia. It really stands out, though, when it is an Italian domain (in Italian), with an English summary (excerpt). The pro of using this dork is that it is fairly easy to spot a lure domain/article. The downside to this method is that it will limit the results to .IT TLDs. This method is much more difficult when we use the .COM TLD because you can’t glean anything useful from the web search results unless it’s something like “RentMyPartyBus.com” serving an article something like “1978 Paris accord”.
Dorking ZIP/JS servers:
The Gootkit delivery system will serve the fake forum from a compromised site, and that fake forum will serve a link to another compromised site that will serve the malicious ZIP/JS file. It appears that sometimes the ZIP/JS server will also include lure articles, but sometimes they do not. For example, gxtfinance[.]com was observed serving the malicious ZIP/JS files, and gxtfinance[.]com also serves lure articles. However, colliercpas[.]com was observed serving the malicious ZIP/JS, but they were not observed to serve any lure articles. It is a benefit to investigate this because it enables an analyst to find compromised domains that aren’t easy to find with simple dorks (.COM vs .IT).
ChatGPT/Local LLM:
I use ChatGPT and a Local LLM. For ChatGPT, I use the paid version ($20 a month) using ChatGPT4. For the LLM, I use LM Studio with one of the Dolphin models from TheBloke on Hugging Face (huggingface.co). These are free to run on your computer.
The ChatGPT results are better. The results are returned much faster. The quality of the response is normally what I need on the first try. One issue is that I pay for ChatGPT, not the API access. This is not an issue for small scale and exploration tasks, but it will not be feasible for the crawler. I don’t feel like paying for the API access. The snip below shows ChatGPT generating search terms to search for Gootkit lure articles.

For the Local LLM, the results can be limited – depends on which model I use. I use TheBloke/dolphin-2.7-mixtral-8x7b-GGUF (https://huggingface.co/TheBloke/dolphin-2.7-mixtral-8x7b-GGUF). The Q4_0 is faster, but the quality is so poor that it doesn’t make sense to use it. The Q8_0 is slower, but it provides correct results. The Q8_0 results are still inferior to ChatGPT at the moment. I don’t think an LLM ran locally on a regular computer will ever be as good as a paid AI service that uses cloud resources. Once I got it figured out, the LLM met the needs because I only use it to generate take the previously observed lure article titles, and random combinations of strings that could be used in a dork: like “enterprise agreement”, “rental agreement”, and “rental contract”.
Overall: both are good for generating output that can provide a combination of words to be used in dorks.
Urlscan.io
Urlscan.io could be used to find additional lure articles via the search query: “domain:thedomain.com”. This will require someone to have previously ran a public scan on a lure article, or you will need to run it manually or via the API. One cool thing is that the Gootkit lure system doesn’t appear to filter out urlscan’s “headless” (https://urlscan.io/docs/faq/#:~:text=Q%3A%20How%20does%20urlscan.io%20work%3F) user agent. The drawback is that urlscan will only scan a URL you provide. It could crawl the Gootkit domain for the rest of the Gootkit lure articles hosted on a given domain, but you’d have to do this programatically. This would only work if the fake forum wasn’t loaded during the scan. When the fake forum is loaded, it overwrites any links to the previous/next article. At the time of writing, you can jump on the free tier (https://urlscan.io/pricing/) and run 5,000 public scans a day and get 1,000 search results per day; the free tier may be good enough for a hobbyist like me. At the bare minimum, my takeaway from this would be that when I find lure articles, I should run a urlscan on the lure URL, so that future researchers can find them.
I ran a quick dork and copied the URL for the second result below:

I ran a scan in urlscan.io and the snip below shows the scan results at https://urlscan.io/result/e253a066-0541-4a13-addc-230fc0410ff5/.
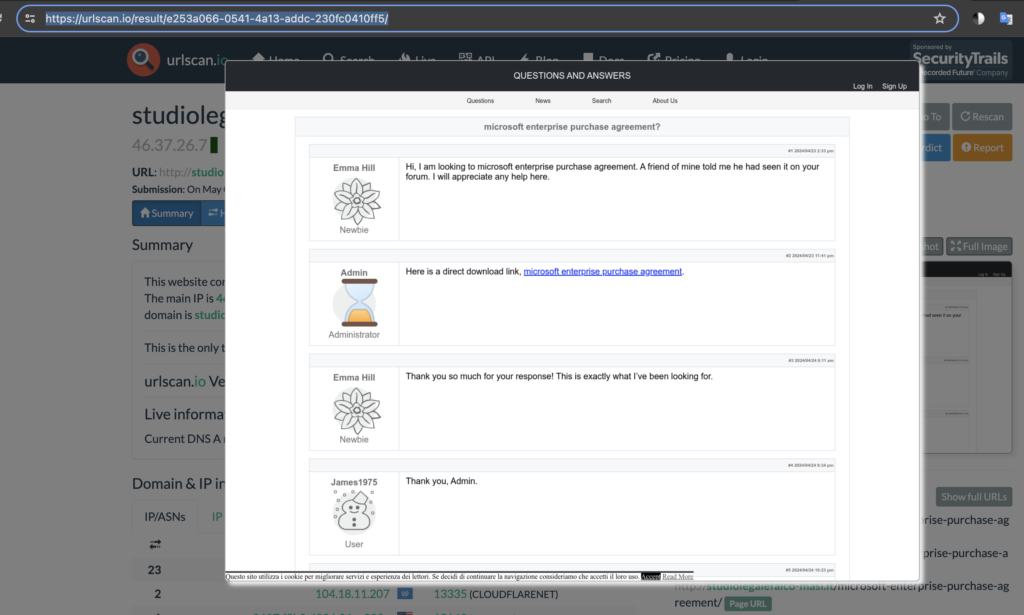
It’s cool because it shows the fake forum was loaded and computed, but it overwrote the links to the previous/next articles as seen in the snip below – it only contains the link to the malicious ZIP/JS:
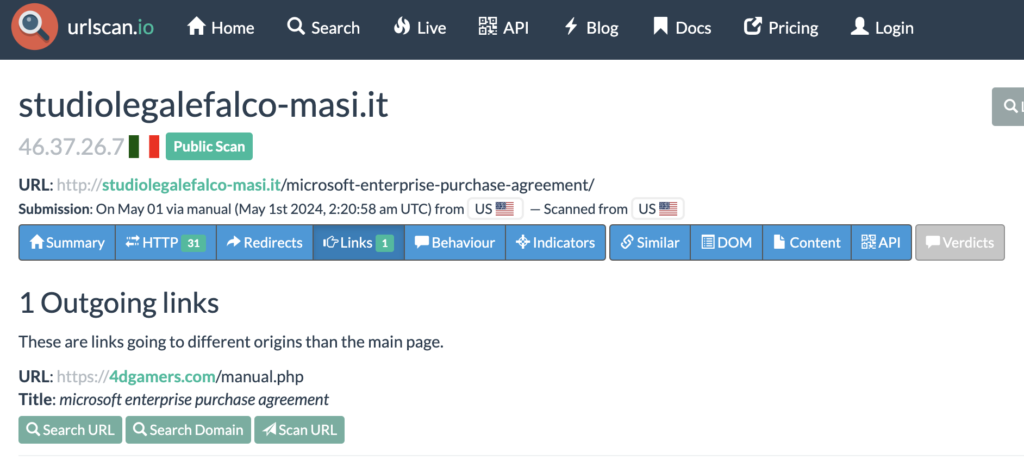
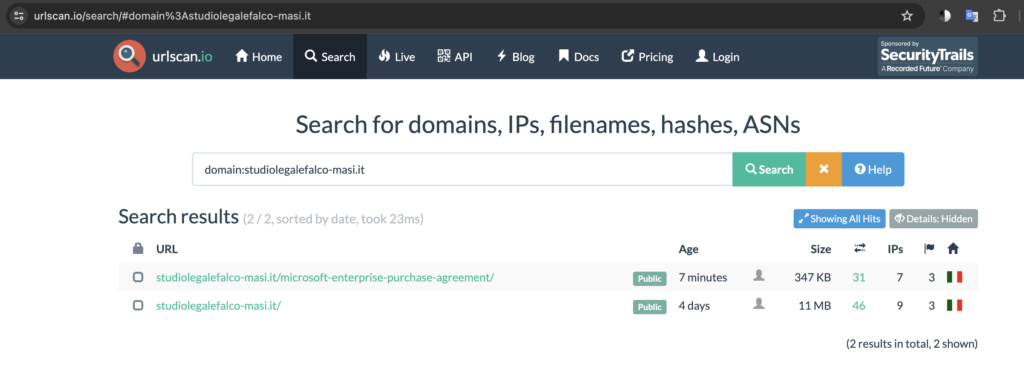
Now when I search for the domain in urlscan.io, I can see the previously scanned domains as seen below (https://urlscan.io/search/#domain%3Astudiolegalefalco-masi.it):
Virustotal
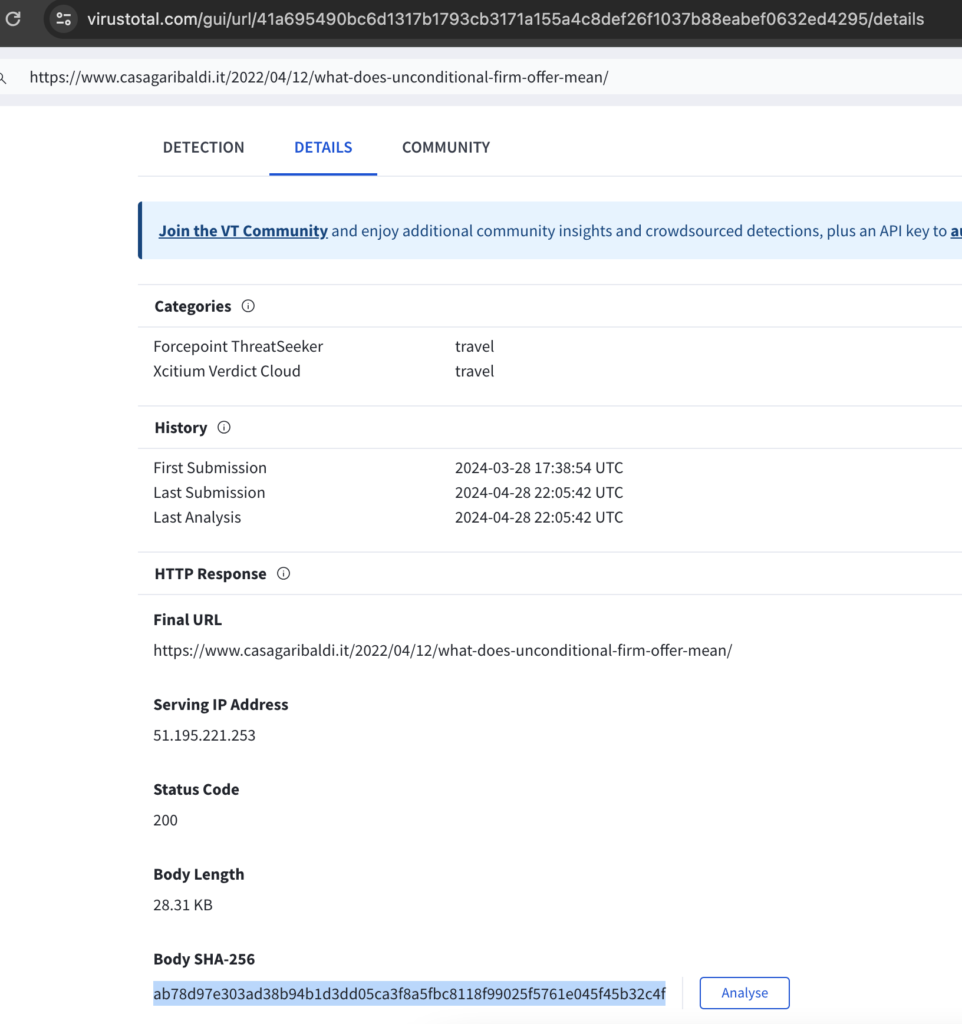
Virustotal could also be used, but it would also require the domains and lure article URLs to have been previously searched by someone else. One thing to remember with Virustotal is that there a URL scan and file scan are different. For example, https://www.virustotal.com/gui/url/41a695490bc6d1317b1793cb3171a155a4c8def26f1037b88eabef0632ed4295 is the VT results page for https[:]//www[.]casagaribaldi[.]it/2022/04/12/what-does-unconditional-firm-offer-mean/. You can see that it is just the URL result. There isn’t much useful info on it except that the body hash is ab78d97e303ad38b94b1d3dd05ca3f8a5fbc8118f99025f5761e045f45b32c4f as seen below:
The VT URL for the file at https://www.virustotal.com/gui/file/ab78d97e303ad38b94b1d3dd05ca3f8a5fbc8118f99025f5761e045f45b32c4f/details is seen below. The interesting part is that the previous/next lure URLs are listed in the Anchor HREFs section.
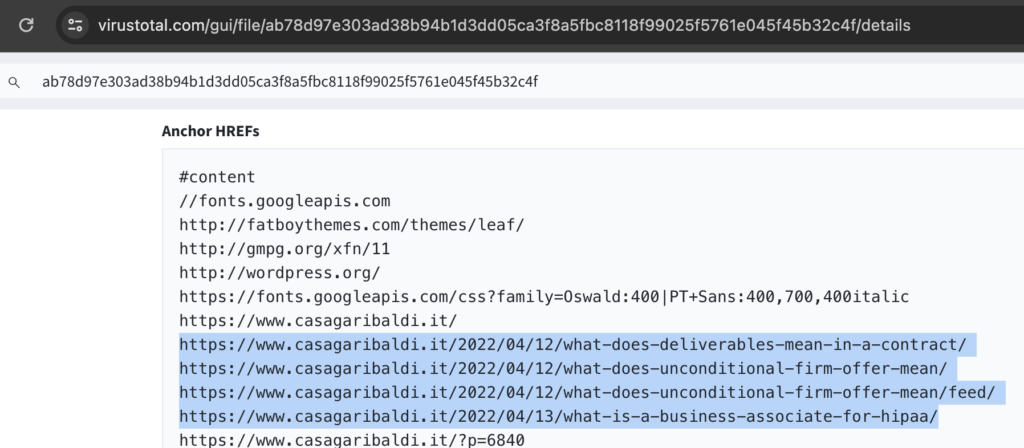
Additionally, viewing the Script Tags shows the JS call for the forum loader, and this could also be used to confirm this is a Gootkit lure article.
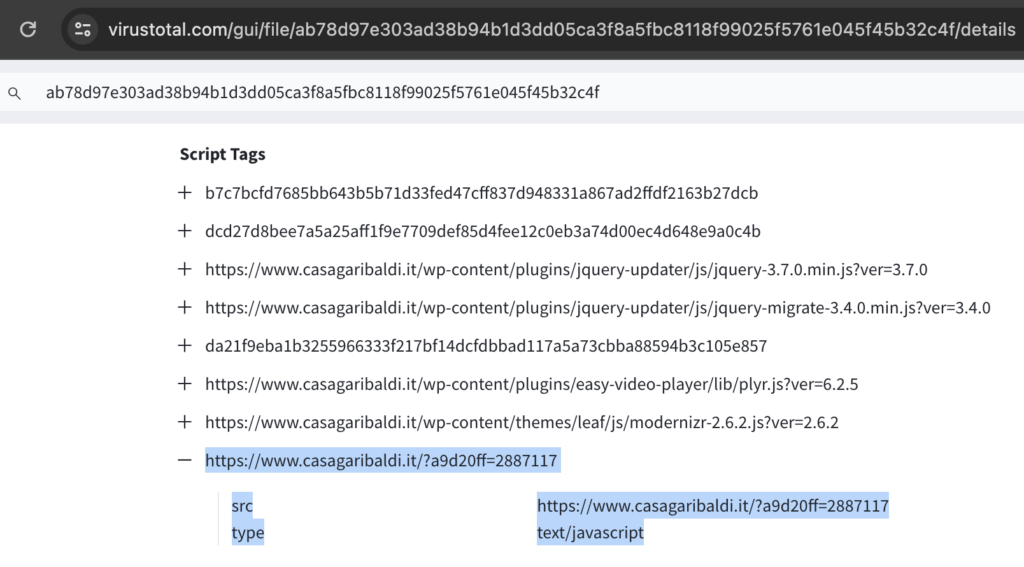
Just like with urlscan.io, it would benefit future researchers to submit the URLs, and analyze the files. It would also benefit other researchers to create comments.
Research into lure article ideas:
Semrush:
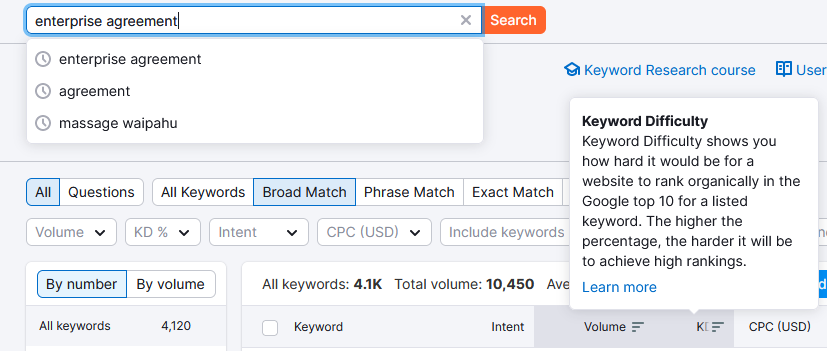
Semrush requires an account, but doesn’t need to be a paid account. It’s a bit confusing because it appears to mislead you into thinking you need a trial account. It appears to be a tool that could be useful for finding current niche search terms. The snips below show the crude steps to find them. Click Keyword Magic Tool, enter the terms in the bar, click search. The default sort is descending by volume, but you can sort it by “KD” (Keyword Difficulty). The lower the number, the easier it is to get on the top of the page. However, while taking the snips, I exceeded the 10 free daily searches, so I can’t show you what it looks like after that.

Google Keyword Planner:
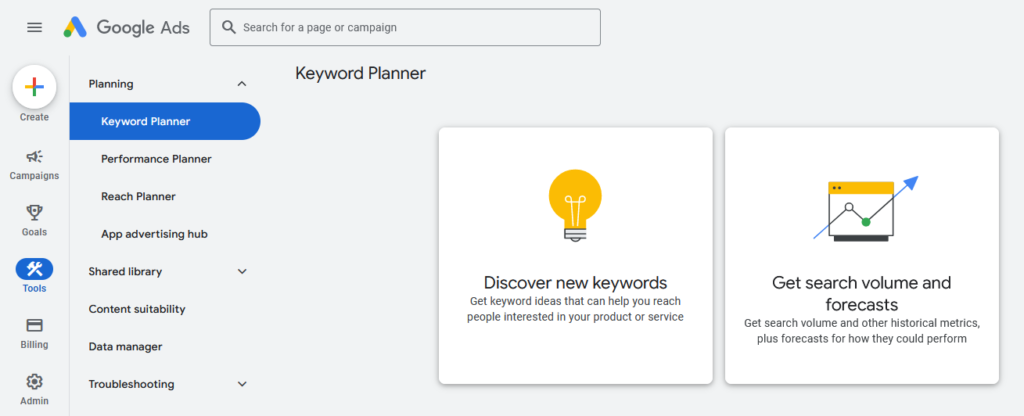
Google Keyword Planner is a free resource. It requires you to create a Google Ads account, but it doesn’t require a campaign. It can be used for search terms. Like Semrush, it also shows the competition metric that shows how hard it would be to get top of page. This resource could be used to harvest unique article titles that are niche enough for the highest success probability.


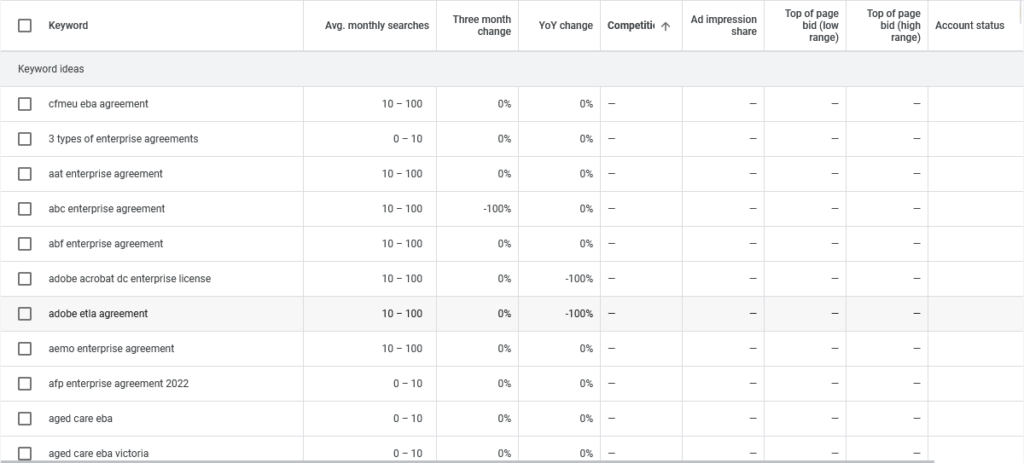
Let’s examine the top of the list: “cfmeu eba agreement”.
A quick search of that term looks promising:

As we see in the snip above, results one and three appear to be malicious. The domain of the first result should be for a music streaming service of some sort, and the third result should be some kind of magazine. We will explore these to domains.
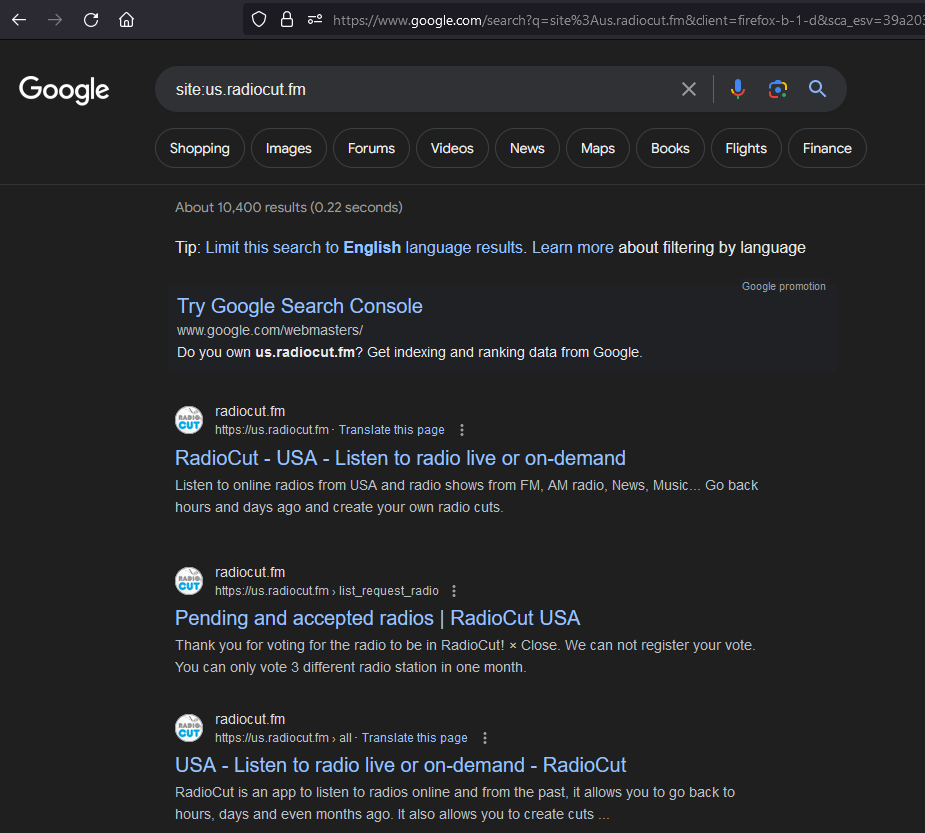
The dork below shows us that it does appear to be a radio streaming service.
We can narrow the dork down to include “agreement”, so that we can make a better guess into if the site is serving lures. The snip below shows us that the domain is serving articles that don’t seem to be related to the music streaming theme.
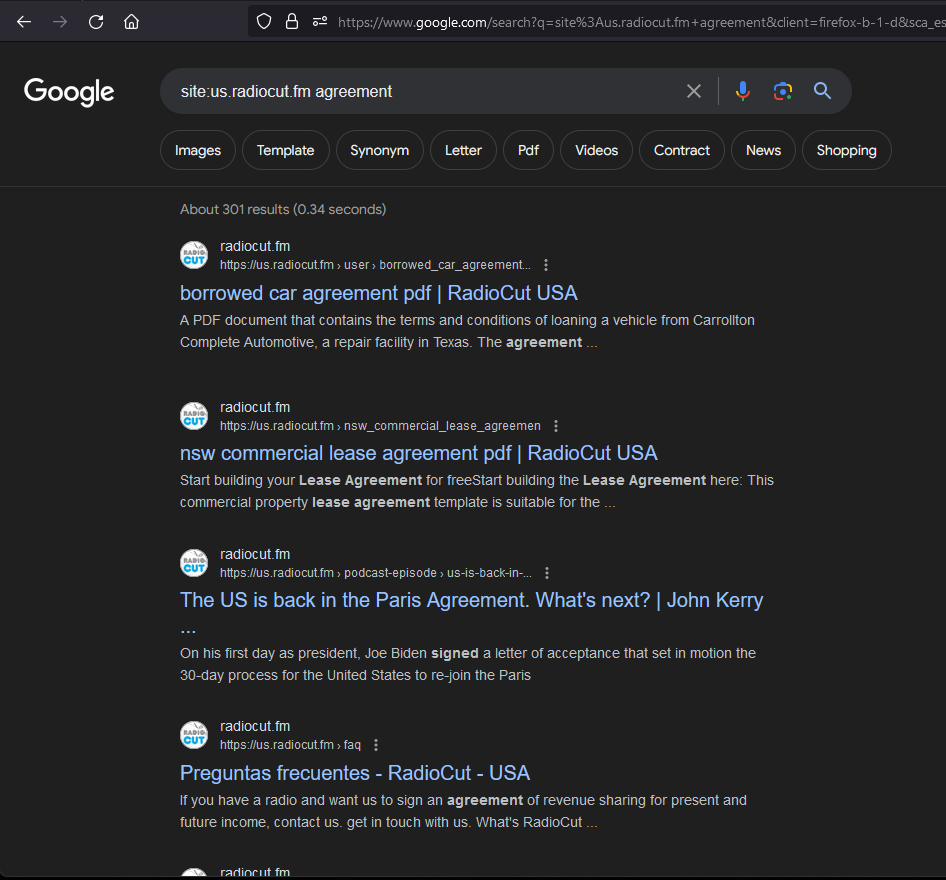
I suspect these are malicious. Even if it is not Gootkit, it is likely a malicious lure.
When I browse to it, I get a 404 as seen below:
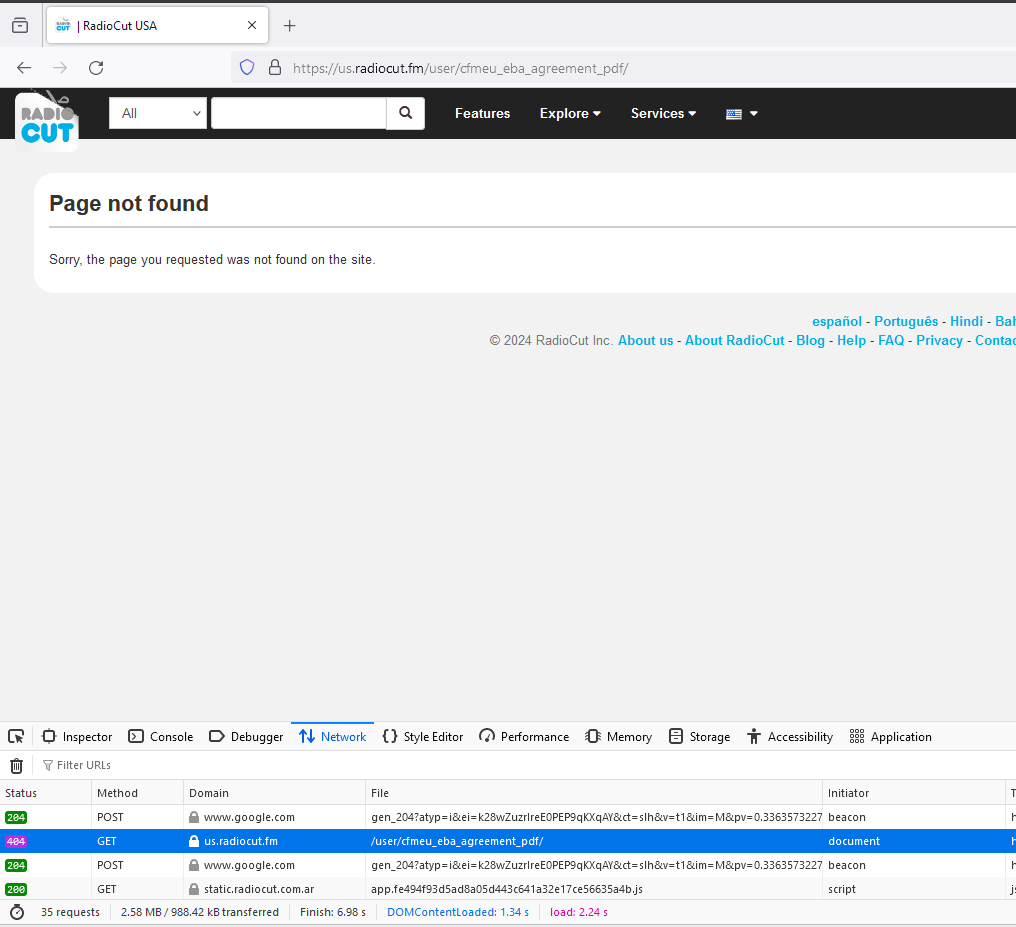
After analysis, it appears that a threat actor may have been creating usernames that were search terms. I assume the user’s profile page may have served nefarious content, but the user accounts appear to have been removed. The snip below shows that there are many users that end with “pdf” in their usernames.

The third result, imagazinebd[.]com will hopefully be better.
After clicking the link with developer tools loaded, we see that sweet-sweet call to the fake forum loader (/?afe619a=7447942).

Success! This is validating news!
Semrush and Google Keyword Planner are tools that the Gootkit operator probably uses (and other lure-based operators probably use this too) to find lure article topics. I have shown that the least competitive search term containing “agreement” (“cfmeu eba agreement”) was a keyword combo that returned a Gootkit lure article in the top of the page. This is exciting! It is great news because it will allow future researchers to find Gootkit lure domains that aren’t limited to peculiar TLDs.
In a future article, I’ll explore using the Google Ads API to see if we can find search terms programmatically.
Summary:
AI can be used to find general terms to search for Gootkit lure articles, but it is more useful for specifying to search using foreign TLDs because lures with .COM TLDs are more difficult to assess without accessing it. Search keyword tools like Semrush and Google Keyword Planner appears to be very useful to find low competition search phrases that are used to create Gootkit lure articles. When you find a lure article and get the domain that is serving the ZIP/JS file, you can craft a dork to find the lure articles hosted on that server. Urlscan.io can be used to visit potential Gootkit lure articles if you don’t have a sandbox readily available; it will also help future researchers. You could also use VT to verify if an article is a Gootkit lure, and you can use it to find the previous/next lure articles on the domain.
What’s next:
In future articles we will explore tasks like using the Google Ads API to find search terms programmatically, using API to perform Google/Bing searches, using the free urlscan API to scan potential lures and verify if it has the fakeforum loader request, using the VT API to verify a Gootkit lure and to find the previous/next article in the Anchor HREFs section.
[…] is Ghana, Cambodia, and Brazil so interested in USPS Templates? Gootkit Search Term Research Indeed Lure Spotted! Starting SocGholish Research Is Gootkit Updating Their C2 […]